Truto RapidBridge Overview
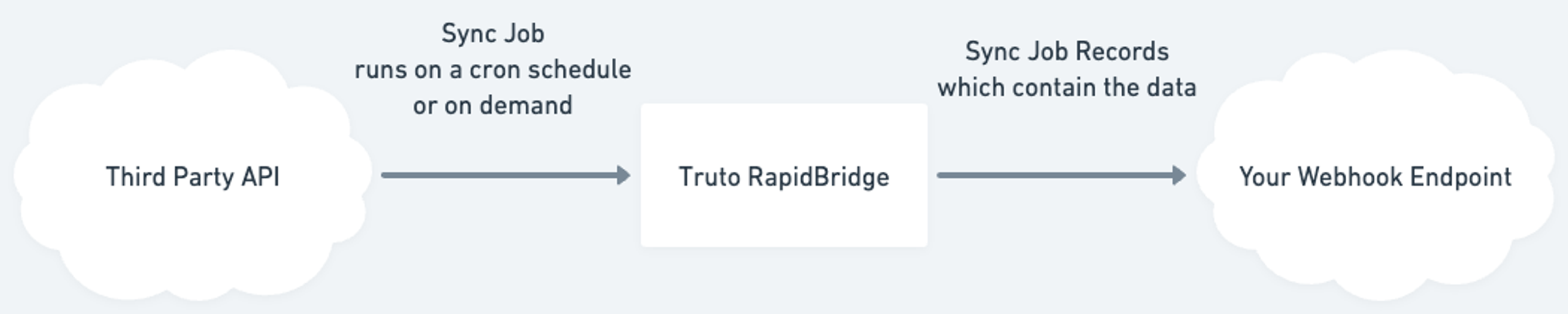
When developing integrations, it's common to pull data frequently from third-party APIs. This usually involves creating a scheduling system. RapidBridge simplifies this process. It manages the scheduling, retrieves data from the Unified and Proxy APIs, and forwards the results to a webhook endpoint in Truto, either on demand or based on a schedule.
How it works
Start by setting up a Sync Job. This is essentially your plan, specifying which data resources you aim to synchronize. Say you want to sync tickets, customers, and organizations from Zendesk; you lay out these specifications in the Sync Job.
You can create and manage sync jobs from the dashboard under Sync Jobs in app.truto.one. See Using the Sync Jobs UI for a walkthrough of the list, detail tabs, runs, schedules, and templates.
Implementing this plan against an account is termed a Sync Job Run.
To initiate a RapidBridge Sync Job Run, you'll need:
- The Sync Job's ID
- The target integrated account
- The webhook endpoint's ID stored in Truto
Here's the process in action:
- Truto initiates with a
sync_job_run:startedmessage. - It begins to retrieve resources. For each fetched resource, it communicates with the API endpoint, sending the acquired data to the webhook, tagged as
sync_job_run:record. - The webhook needs to respond with a 200 status code for Truto to proceed with the next resource or to continue the sync.
After all data resources are synchronized, Truto sends a sync_job_run:completed notification.
Webhook event sequence
-
sync_job_run:started: This event marks the initiation of the syncing process. Before any data is fetched, this event is triggered. The webhook endpoint should acknowledge receipt by responding with a 200 status code. If you want to run any validation and stop the sync process, you can respond with a 400 status code. -
sync_job_run:record: This event is at the core of the data synchronization. Each time Truto fetches a resource, whether it's a single item or a batch, it sends the data to the webhook endpoint under this event label. To ensure smooth processing, the webhook endpoint should respond with a 200 status code. Once received, Truto proceeds to the next resource or batch. This process repeats until all designated resources are synchronized. -
sync_job_run:record_error: Not all fetches are guaranteed to be smooth. In cases where an error arises during data retrieval, this event is sent to notify of the issue. The occurrence of this event largely depends on theerror_handlingsetting. If set to its default value,ignore, this event is triggered. For Truto to continue with the sync or to move to the next resource, the webhook endpoint should send back a 200 status response. -
sync_job_run:rate_limited: Sometimes, the rate of data requests may exceed the allowed limits of the underlying API. When this happens, Truto sends this event to indicate a rate limit scenario. The syncing process pauses temporarily during this period. Once the limitation period is over, Truto resumes the sync process, starting with thesync_job_run:recordevents. As with other events, the continuation relies on receiving a 200 status response from the webhook endpoint. -
sync_job_run:completedorsync_job_run:failed: Every process has its end. Once all resources are fetched and synchronized (or if an unresolvable error occurs), one of these concluding events is sent. Thesync_job_run:completedevent indicates a successful synchronization. On the other hand, if a critical error halts the process and theerror_handlingsetting is marked asfail_fast, thesync_job_run:failedevent is sent to signify an incomplete or unsuccessful sync.